Patterns as complexity inhibitors
D. L. Parnas wrote
Whatever your language or programming paradigm, change is inevitable, so the cost of change always decreases when you cut up your program along those change boundaries. The software design patterns of the GoF book helped here by suggesting a collection of ways to decouple code using abstraction and inheritance. But we seldom ask what should call us to action. When should we decouple things? Patterns help us answer this when they include the criteria for when to apply them. Or, put another way, if they are problem-centric, they tell us when to act.
I am referring again to the foreword from
The cost of complexity
Complexity increases the cost to grow or change. What Christopher Alexander
wrote in
We can see the same situation with large programs. Any sufficiently large program has many connected pieces where changes in one area lead to changes in many others. Ideally, we would enable changes across all project areas, with every change isolated to a single location, and not need to make multiple adjustments throughout the project.
Christopher Alexander’s approach was a universal principle of deciding where to draw the lines by finding the smallest number of connections under change[Notes64]. Rather than map out a project by preconceived concepts and familiar hierarchies, he tried to stay objective about each piece of the final product. He only drew connecting lines between elements that changed in tandem.
For example, if I try to build a code project along the same lines, I can start with a file format I use when storing configuration. If the loader only loads to a simple accessible data structure and can serialise that simple structure back out again, we’ve connected the change requirements of serialising and de-serialising with the File Loader class. Changes to the configuration file format affect both reading and writing. The loader doesn’t provide an API to access the configuration data structure from within the application. We delegate that job to a separate set of methods or objects: the Config API.
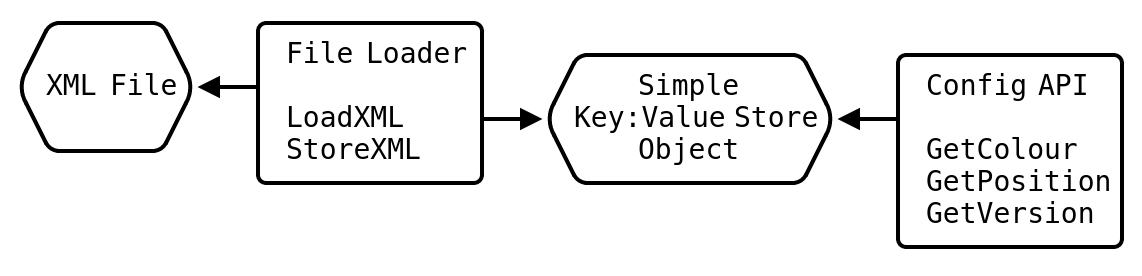
Changing the configuration file format affects the serialisation layer but has little to no effect on the things that wish to be configured. Changing the API for using configuration data loaded from the configuration file would seldom affect the file format. It only affects code using the library to fetch configuration values. Therefore, the configuration file format is separable from the configuration data API. The simple data structure object in the middle is a complexity inhibitor.
Now, think about how projects change. New configuration data is the most common. But, as we know from the long history of relational databases, it’s almost always possible to migrate data from one schema to another. Adding new ways to access the data is another routine change, such as loading from a database or through IPC or other direct memory access. In any case, the reader/writer is the only aspect that needs to change. Even migrating data from one type of reader to another is straightforward so long as the loaders load into the same simple intermediate data structure.
The other recurring change is an extension to the query language for configuration.
As you can see, it’s quite a departure from how we usually think about modularisation. This process separates the concerns cleaner than an object-oriented design normally would. The simple data structure in the middle is completely exposed but meaningless data, which seems to go against the principle of encapsulation, but does it? The point of encapsulation is to provide a succinct and simple way to query and manipulate information in the system. I think the usage API does that.
What about data-hiding? If the loader is provided with a place to store the data and the location is handed off to the usage API, then I feel that is covered as well via a configuration object, coordinator, or mediating process. Neither component owns the simple data-structure, but that changes much less frequently, so we cut across that line.
But what if the simple data structure does change? Sometimes, more advanced queries are required, and you wonder if your XML file shouldn’t have been an SQLite database. But wait, rather than implement queries on your simple data structure, take the stairs, walk across the bridge, descend at the other side, and start using SQL queries.
 Adding queries to a simple data structure is fast but not clever.
Adding queries to a simple data structure is fast but not clever.
We might have swapped out the simple data structure for a database, but we only needed to change one thing at a time.
- Step one allowed us to read and write SQLite db files to and from the simple data structure.
- In step two, we migrated1 from storing XML to an SQLite file while maintaining the simple data structure.
- Then, in step three, we migrated from querying the simple data structure to directly querying the SQLite database.
When we link parts of a design that aren’t strictly necessary, we couple them
and make them more complex. Deriving patterns using the process from
for this step, we can load the XML into the intermediate representation, then write it out to the database format.