An example
In this section, I attempt to create a pattern story, showing how it might look when following some of my advice. Diagrams show both a before and after state. Look at how it defines the problem as an anecdotal conflict and suggests a path towards a solution. It’s not perfect, but hopefully, this provides a concrete alternative to some of the more theoretical work covered thus far.
The pattern is part
CAVEAT: This next part is probably not the best way to explain a pattern, but this story-like flow may be more comprehensible because it contains elements of the pain of the problem and shows the steps.
1. The problem – My API has a lot of data-coupling getter methods.
When your software grows, sometimes it gains some non-complex but large APIs. These are shallow, simple APIs with many methods, each used by only one or two other objects. This usually happens when one subsystem has grown to solve the problems of many other systems and has taken responsibility for them, even though they are not best suited to solve all the problems.
When is such a system not best suited? When the system knows less about the domain of the solution than the caller.
Software in this state tends to have many methods with overlapping names. Many small specific public methods massively outnumber the private implementation. Many of the individual methods of the public API will not be used by more than one external entity. Some methods require otherwise unrelated data to be managed by the module.
Each external entity has a thing they care about, their domain, and the central module provides a specialised port to connect to. In addition, the central object often owns the data, but its primary responsibility is handling requests, not data transformation itself; it lacks domain knowledge.
We’ll consider an application to help budding authors find information on books they have read, or should have read, and help them create good bibliographies and notes.
1.1 My problem
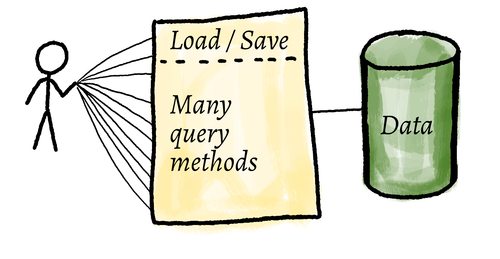
My application, Library, was an opaque object with lots of methods. It
relied on two other classes, Book and Note. The support classes were
trivial data objects.
def GetAuthors(self):
return self.author
def GetTitle(self):
return self.title
def GetPublicationDate(self):
return self.date
One method on the main Library object was to fetch the notes for a book, as I
thought storing the notes directly with the bibliography information was a bad
idea.
def GetNotes(self, book):
if isinstance(book, Book): # if a book, turn into book_id
book = book.reference_id
return [note
for note in self.notes
if note.reference_id == book]
There was a trivial method for getting the list of all the books.
def GetBookList(self):
return self.books
However, the whole list was quite large, so it was not easy to work with directly. Instead of using that method alone, I wrote new methods to fetch by different criteria.
def GetBooksByAuthor(self, author_name):
return [book for book in self.books
if author_name in book.GetAuthors()]
def GetBooksInDateRange(self, start_date, end_date):
return [book for book in self.books
if start_date <= book.GetPublicationDate() <= end_date]
def GetBooksMatchingTitle(self, match):
return [book for book in self.books
if match in book.GetTitle()]
And when I say the book list was very large, I mean it. Even filtering down this far was not enough in some cases. To help, I added some even more specific fetching functions.
def GetBooksMatchingSubjectWithNotes(self, match):
return [book for book in self.books
if match.lower() in book.GetTitle().lower()
and len(self.GetNotes(book))]
def GetBooksByAuthorInDateRange(self, author_name, start_date, end_date):
return [book for book in self.books
if author_name in book.GetAuthors()
and start_date < book.GetPublicationDate() < end_date]
def GetBooksMatchingSubjectButNotByAuthor(self, subject, author_name):
return [book for book in self.books
if author_name not in book.GetAuthors()
and subject.lower() in book.GetTitle().lower()]
def GetBooksInDecadeSortedByRef(self, decade_start):
return sorted([book for book in self.books
if decade_start <= book.GetPublicationDate()
and book.GetPublicationDate() < decade_start + 10],
key=lambda x: x.reference_id)
After a while, I realised that some duplicated code had led to some bugs, and adding new functions wasn’t getting easier to get right. I would copy-paste the closest method and make some changes. This is not the cleanest of coding practices and is obviously prone to copy-paste errors.
2. The forces – I want more but need fewer.
It all came to a head when I hit two opposing forces:
- I wanted to add even more queries, but it seemed silly to keep adding them this way.
- I needed to remove all the queries to do with notes.
I needed to add a method that would select the books referenced in my new work,
Programming Design-Patterns for Job Security. I wanted to add something like
GetBooksWithNotesIncludedInWork, but that would couple the bibliography
software to my notes objects even more.
I thought I could make something that grabbed all the notes, checked they were
included in my new book, and then use that filtered list in a new function
called GetBooksWithNotesInThisList(self, note_list). That seemed like an
almost workable but awful plan.
But then I hit a real problem. Someone I worked with wanted to use part of my
software. They needed a bunch of different queries for their books, such as
GetBooksWithHighPageCount and GetBooksWithDimensions(Width, Height), as they
were trying to write some software that automatically found a nice way to stack
their bookshelf while also maintaining author name ordering where possible.
My bibliography didn’t have the dimension or page count data, and adding it seemed wrong. I didn’t need those functions, and they would have just cluttered my beautiful API! So, I wanted to make it such that they could add their own data about the books, in the same way I added notes, but I also had to make it in a way that I didn’t need to share my note data when sharing the bibliography data, as I didn’t want them reading my notes.
Refactoring hygiene
Before refactoring, you should always have tests to prove your actions haven’t broken anything. I wrote a few use cases to generate output data to confirm things were working. I used approval tests to verify each refactoring step by comparing text output.
library = Library()
print("Books with notes, on the subject of programming")
print_books(library,
library.GetBooksMatchingSubjectWithNotes(
"program"))
print("Books by Takashi Iba")
print_books(library, library.GetBooksByAuthor("Takashi Iba"))
print("Early books by Christopher Alexander")
print_books(library, library.GetBooksByAuthorInDateRange(
"Christopher Alexander", 0, 2000))
print("Books by others on architecture")
print_books(library, library.GetBooksMatchingSubjectButNotByAuthor(
"architecture", "Christopher Alexander"))
print("Books from the 80s, sorted by RefID")
print_books(library, library.GetBooksInDecadeSortedByRef(1980))
This approach might not work for your case, but you will need something that tests at a more abstract level than a typical unit test, such as a behaviour test, because this refactoring changes the API and the participating components.
3. The process
My problem module was a monolith with many methods. Internally, the module talked to a datastore containing data that was not strongly coupled but shared the same backing store and access point.
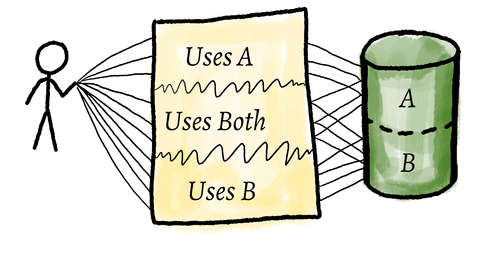
Any solution would include some way to GetBooksBySomeKindOfQuery(Query). I
wanted to decouple all this, so I surveyed the problem. As a first step, I realised
all the queries already operated on data I could get via the public API of the
Book object. So, I started by extracting each function out into public free
functions.
Step 1: Extract to free functions
def GetBooksMatchingSubjectWithNotes(selflibrary, match):
return [book for book in selflibrary.booksGetBookList()
if match.lower() in book.GetTitle().lower()
and len(selflibrary.GetNotes(book))]
def GetBooksByAuthorInDateRange(selflibrary, author_name, start_date, end_date):
return [book for book in selflibrary.booksGetBookList()
if author_name in book.GetAuthors()
and start_date < book.GetPublicationDate() < end_date]
def GetBooksMatchingSubjectButNotByAuthor(selflibrary, subject, author_name):
return [book for book in selflibrary.booksGetBookList()
if author_name not in book.GetAuthors()
and subject.lower() in book.GetTitle().lower()]
def GetBooksInDecadeSortedByRef(selflibrary, decade_start):
return sorted([book for book in selflibrary.booksGetBookList()
if decade_start <= book.GetPublicationDate()
and book.GetPublicationDate() < decade_start + 10],
key=lambda x: x.reference_id)
The usage of the methods changed, but only a little. Mostly, as is usual when you migrate to a free function, the object slides into the first argument.
library = Library()
print("Books with notes, on the subject of programming")
print_books(library,
library.GetBooksMatchingSubjectWithNotes(
library, "program"))
print("Books by others on architecture")
print_books(library, library.GetBooksMatchingSubjectButNotByAuthor(
library, "architecture", "Christopher Alexander"))
print("Books from the 80s, sorted by RefID")
print_books(library, library.
GetBooksInDecadeSortedByRef(
library,
1980))
The system now looked more like this. There was still a monolith for accessing data, but all the coupling was firmly in the realm of my free functions.
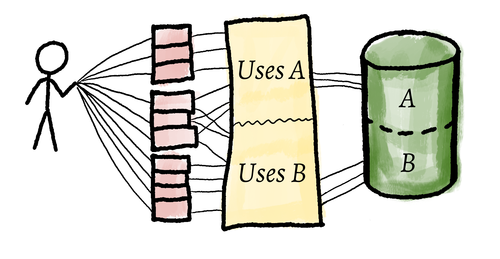
Taking stock of the situation, I could now see a way forward for my second force. I had to split the data handling to provide my co-worker with a version without note data support. I needed to stop using the one big data class and split it into a Library for the books and a Notes object to hold my notes. Making this change was relatively easy, but I also took the step of removing all the finding methods from the library at the same time, as I knew I would not need them anymore.
Step 2: Decouple false-coupled data
def GetBooksMatchingSubjectWithNotes(library, notes, match):
return [book for book in library.GetBookList()
if match.lower() in book.GetTitle().lower()
and len(librarynotes.GetNotes(book))]
The functions don’t look much different. The usage was still very similar, but I now had an extra parameter when I needed both books and notes in the query.
library = Library()
notes = Notes()
print("Books with notes, on the subject of programming")
print_books(librarynotes,
GetBooksMatchingSubjectWithNotes(
library, notes, "program"))
print("Books by others on architecture")
print_books(librarynotes, GetBooksMatchingSubjectButNotByAuthor(
library, "architecture", "Christopher Alexander"))
print("Books from the 80s, sorted by RefID")
print_books(librarynotes, GetBooksInDecadeSortedByRef(library, 1980))
The system was now entirely decoupled in terms of data stores. I could replace each store independently without causing any changes to propagate through the system.
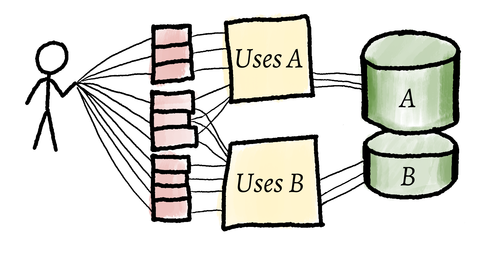
Turning point
I really could have stopped there if time had been very tight. My co-worker would have been able to use the book-related operations and the Library class. My Note code could be stripped and put in a separate file. But of course, it was quite ugly and still suffered from the first force problem. Adding new queries would not be easy, and copy-pasting would remain error-prone.
I saw all the patterns of repetition clearly. Most of these functions had the same
return type as the Library.GetBookList() method. So, I turned them
into filters, filtering that return value.
Step 3: Refactor to filter operation
def WithNotes(books, notes):
return filter(lambda book: len(notes.GetNotes(book)), books)
def ByAuthor(books, author_name):
return filter(lambda book: author_name in book.GetAuthors(), books)
def InDateRange(books, start_date, end_date):
return filter(lambda book: start_date <= book.GetPublicationDate() <= end_date, books)
def NotByAuthor(books, author_name):
return filter(lambda book: author_name not in book.GetAuthors(), books)
def MatchingSubject(books, match_string):
return filter(lambda book: match_string.lower() in book.GetTitle().lower(), books)
def SortedByRef(books):
return sorted(books, key=lambda book: book.reference_id)
def InDecade(books, decade_start):
return InDateRange(books, decade_start, decade_start+10)
This also meant I only had to push lists of books into the calls rather than provide the whole Library object. I splintered off the filters that were intersections. I could then rewrite some of my earlier queries in a more reusable manner.
library = Library()
notes = Notes()
print("Books with notes, on the subject of programming")
print_books(notes,
GetBooksWithNotes(MatchingSubjectWithNotes(
library.GetBookList(), notes,
"program"),
notes))
print("Books by others on architecture")
print_books(notes, GetBooksMatchingSubjectBut(NotByAuthor(
library, "architecture".GetBookList(), "Christopher Alexander"), "architecture"))
print("Books from the 80s, sorted by RefID")
print_books(notes, GetBooksInDecadeSortedByRef(InDecade(library.GetBookList(), 1980)))
But then, it seemed a bit funny that I needed a function for NotByAuthor as
well as ByAuthor. But there’s no way to un-filter a list. Again, I noted
the repetition in each filter function and decided to keep filtering, but only
once, and find a way to join those filters together.
Step 4: Refactor filters to specs
The
For this step, I decided to implement my spec objects as lambdas. Instead of
filtering by a NotByAuthor(author_name) spec, I would filter by a Not(spec)
spec, which was a kind of ByAuthor(author_name) spec.
def WithNotes(books, notes):
return filter(lambda book: len(notes.GetNotes(book)), books)
def ByAuthor(books, author_name):
return filter(lambda book: author_name in book.GetAuthors(), books)
def InDateRange(books, start_date, end_date):
return filter(lambda book: start_date <= book.GetPublicationDate() <= end_date, books)
def NotByAuthor(books, author_name):
return filter(lambda book: author_name not in book.GetAuthors(), books)
def MatchingSubject(books, match_string):
return filter(lambda book: match_string.lower() in book.GetTitle().lower(), books)
def SortedByRef(books):
return sorted(books, key=lambda book: book.reference_id)
def InDecade(books, decade_start):
return InDateRange(books, decade_start, decade_start+10)
def And(a, b):
return lambda book: a(book) and b(book)
def Not(a):
return lambda book: not a(book)
I needed to construct the WithNotes spec with the capacity to verify against
the note list. I also needed to construct the ByAuthor spec with an author
name. The verification of the author happens later, but the object (the lambda)
is pending, not actually running until later.
Something strange was going on with WithNotes because it linked the two data
stores together. It felt like an SQL query where I would join two tables. In
any small filtering language like this, there may be times when you realise
you need to think about whether you want to work with the data as a document
store or a relational database. Each has trade-offs. In my case, I
realised that I would be satisfied keeping them separate and treating them as
tables that must be joined.
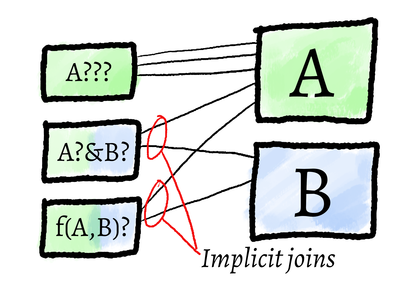
Some prefer a document store approach. Such an approach would mean the data would become coupled again. Coupling can boost performance because you can distribute document processing, but distributing is not always quicker. The choice comes down to the specific problem you’re trying to solve. My problem was coupling, so a spec-level join was my preference.
Of all the free functions, the odd one out was SortedByRef(books), which
was not a spec but a post-process on the output of the filtering operation.
Sorting the data from a query felt familiar to me at the time. Whenever I
queried a database, I would typically SELECT from some tables, have some form
of filtering in the WHERE clause and then have an ORDER BY as the last
step. The final filter was emulating an ordering step. This might indicate
there could also be grouping filters.
So, my use case now looked like this:
library = Library()
notes = Notes()
print("Books with notes, on the subject of programming")
print_books(notes,
filter(
And(WithNotes(notes),
MatchingSubject("program")),
library.GetBookList(),
"program"),
notes))
print("Books by others on architecture")
print_books(notes, filter(
And(MatchingSubject("architecture"),
Not(ByAuthor("Christopher Alexander"))),
library.GetBookList(), "Christopher Alexander"), "architecture"))
print("Books from the 80s, sorted by RefID")
print_books(notes, SortedByRef(
filter(InDecade(1980), library.GetBookList(), 1980)))
I could see how this way of writing queries would be highly extensible. It’s
open to any possible usage. However, it’s very raw, so I took the repeating
pattern of filtering on the result of the Library object’s GetBookList and
put the common code into a new method in the library.
def GetBooks(self, spec):
return filter(spec, self.books)
Once complete, the final use case no longer needs to be concerned with filtering, just the construction of predicates.
library = Library()
notes = Notes()
print("Books with notes, on the subject of programming")
print_books(notes,
filterlibrary.GetBooks(
And(WithNotes(notes),
MatchingSubject("program")),
library.GetBookList()))
print("Books by others on architecture")
print_books(notes, filterlibrary.GetBooks(
And(MatchingSubject("architecture"),
Not(ByAuthor("Christopher Alexander"))),
library.GetBookList()))
print("Books from the 80s, sorted by RefID")
print_books(notes, SortedByRef(
filterlibrary.GetBooks(InDecade(1980), library.GetBookList())))
The result of this work allowed my co-worker to write a spec that didn’t even use the book reference ID. In addition, they sorted by author name in a more traditional way.
def ShorterThan(dimensions, upper_limit):
return lambda x: dimensions.get(x.GetTitle()).Height() < upper_limit
def SortedByAuthorLastName(books):
return sorted(books, key=lambda x: x.GetAuthor()[0].split(" ")[-1])
Final thoughts
It doesn’t matter what language you write in; so long as you can build up a chain of operations, you can use this spec-tree pattern to resolve queries or other problems that look like a small language.